My Research
My current research focuses on developing robust 3D visual representations that bridge geometric reconstruction, semantic understanding, and downstream decision-making. Traditionally, 3D reconstruction has been viewed primarily as a graphics or geometry problem, while reasoning and navigation have been studied separately in robotics. My work connects these areas by exploring how 3D scene representations can move beyond passive reconstruction to become active, useful computational structures for perception, memory, and reasoning in complex real-world environments. I investigate how explicit geometric representations can enhance spatial perception in autonomous vehicles, how representations like 3D Gaussian Splatting (3DGS) can function as a persistent memory for embodied agents, and how geometry-aware representations can improve semantic understanding.
2026
Reconstruction Matters: Learning Geometry-Aligned BEV Representation through 3D Gaussian Splatting
Yiren Lu; Xin Ye; Burhaneddin Yaman; Jingru Luo; Zhexiao Xiong; Liu Ren; Yu Yin.
arXiv preprint 2026
We propose Splat2BEV, a Gaussian Splatting-assisted BEV framework that learns emantically rich and geometrically precise BEV feature representations.
Reconstruction Matters: Learning Geometry-Aligned BEV Representation through 3D Gaussian Splatting
Yiren Lu; Xin Ye; Burhaneddin Yaman; Jingru Luo; Zhexiao Xiong; Liu Ren; Yu Yin.
We propose Splat2BEV, a Gaussian Splatting-assisted BEV framework that learns emantically rich and geometrically precise BEV feature representations.
GSMem: 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning
Yiren Lu; Yi Du; Disheng Liu; Yunlai Zhou; Chen Wang; Yu Yin.
arXiv preprint 2026
GSMem is a zero-shot embodied exploration and reasoning framework that utilize 3DGS as persistent memory.
GSMem: 3D Gaussian Splatting as Persistent Spatial Memory for Zero-Shot Embodied Exploration and Reasoning
Yiren Lu; Yi Du; Disheng Liu; Yunlai Zhou; Chen Wang; Yu Yin.
GSMem is a zero-shot embodied exploration and reasoning framework that utilize 3DGS as persistent memory.
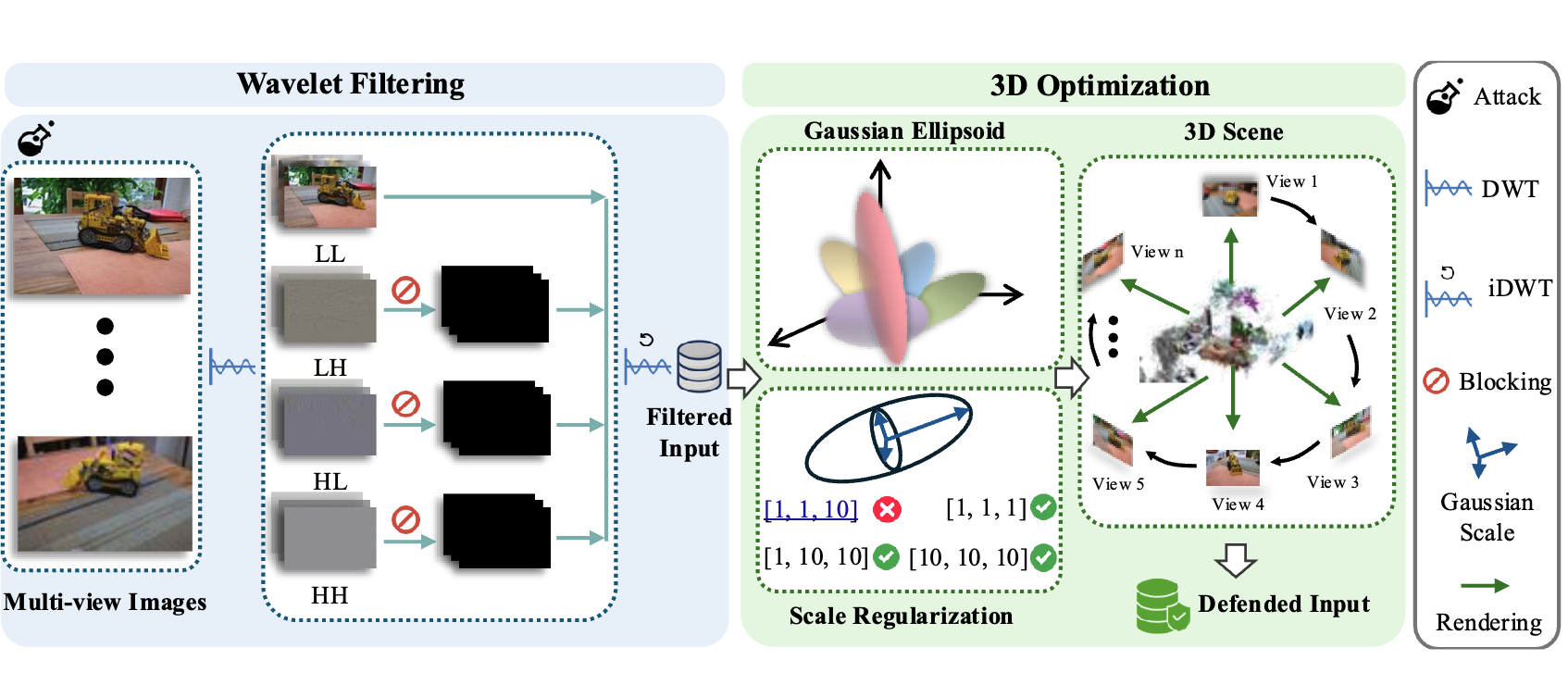
DefenseSplat: Enhancing the Robustness of 3D Gaussian Splatting via Frequency-Aware Filtering
Yiran Qiao; Yiren Lu; Yunlai Zhou; Rui Yang; Linlin Hou; Yu Yin; Jing Ma.
ECCV 2026
We introduce a novel frequency-aware defense strategy DefenseSplat for 3DGS.
DefenseSplat: Enhancing the Robustness of 3D Gaussian Splatting via Frequency-Aware Filtering
Yiran Qiao; Yiren Lu; Yunlai Zhou; Rui Yang; Linlin Hou; Yu Yin; Jing Ma.
We introduce a novel frequency-aware defense strategy DefenseSplat for 3DGS.

AdvSplat: Adversarial Attacks on Feed-Forward Gaussian Splatting Models
Yiran Qiao; Yiren Lu; Yunlai Zhou; Rui Yang; Linlin Hou; Yu Yin; Jing Ma.
arXiv preprint 2026
We introduce AdvSplat, the first systematic study of adversarial attacks on feed-forward 3DGS.
AdvSplat: Adversarial Attacks on Feed-Forward Gaussian Splatting Models
Yiran Qiao; Yiren Lu; Yunlai Zhou; Rui Yang; Linlin Hou; Yu Yin; Jing Ma.
We introduce AdvSplat, the first systematic study of adversarial attacks on feed-forward 3DGS.
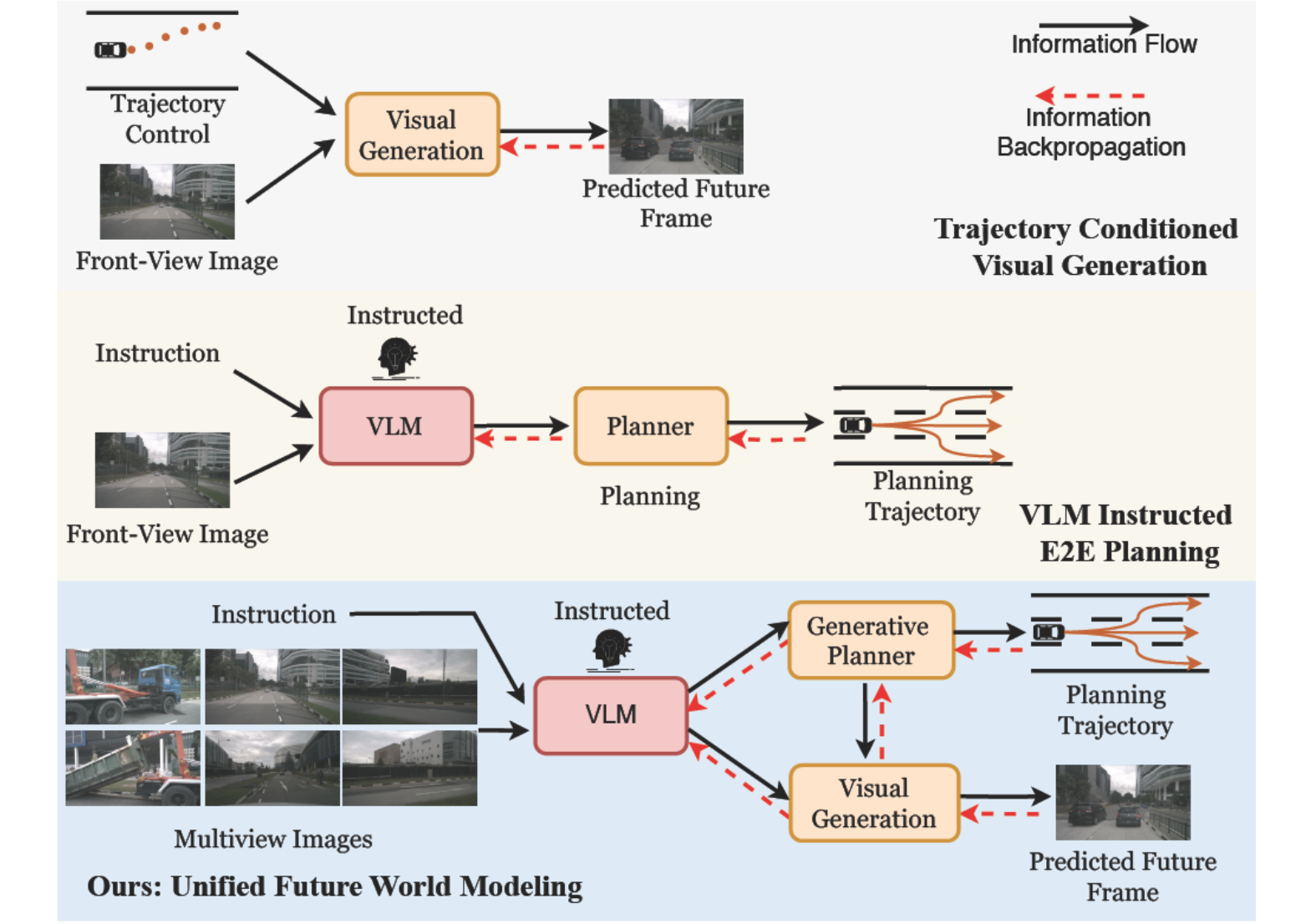
UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Zhexiao Xiong; Xin Ye; Burhan Yaman; Sheng Cheng; Yiren Lu; Jingru Luo; Nathan Jacobs; Liu Ren.
ECCV 2026
We propose UniDrive-WM, a unified VLM-based world model that jointly performs scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture.
UniDrive-WM: Unified Understanding, Planning and Generation World Model For Autonomous Driving
Zhexiao Xiong; Xin Ye; Burhan Yaman; Sheng Cheng; Yiren Lu; Jingru Luo; Nathan Jacobs; Liu Ren.
We propose UniDrive-WM, a unified VLM-based world model that jointly performs scene understanding, trajectory planning, and trajectory-conditioned future image generation within a single architecture.
2025
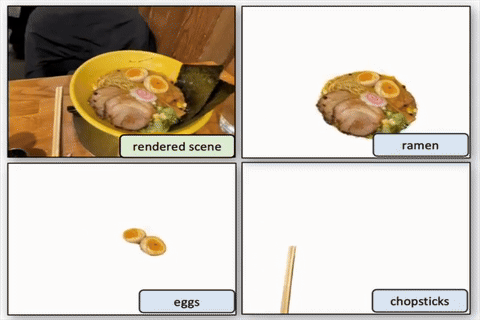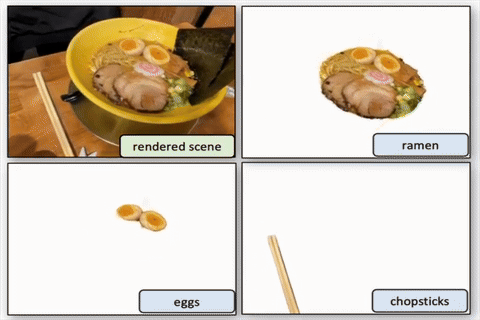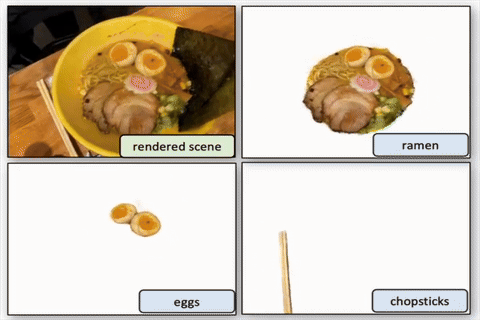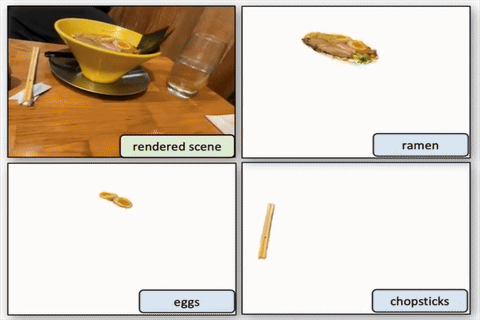
Segment then Splat: Unified 3D Open-Vocabulary Segmentation via Gaussian Splatting
Yiren Lu; Yunlai Zhou; Yiran Qiao; Chaoda Song; Tuo Liang; Jing Ma; Yu Yin.
NeurIPS 2025
We propose Segment then Splat, which performs segmentation before reconstruction by dividing Gaussians into object sets upfront, eliminating semantic/geometric ambiguity and accelerating optimization.
Segment then Splat: Unified 3D Open-Vocabulary Segmentation via Gaussian Splatting
Yiren Lu; Yunlai Zhou; Yiran Qiao; Chaoda Song; Tuo Liang; Jing Ma; Yu Yin.
We propose Segment then Splat, which performs segmentation before reconstruction by dividing Gaussians into object sets upfront, eliminating semantic/geometric ambiguity and accelerating optimization.

Fix False Transparency by Noise Guided Splatting
Aly El Hakie*; Yiren Lu*; Yu Yin; Michael W. Jenkins; Yehe Liu. (* equal contribution)
NeurIPS 2025
We propose Noise Guided Splatting to address false transparency artifacts in 3D Gaussian Splatting by injecting opaque noise Gaussians in object volumes during training.
Fix False Transparency by Noise Guided Splatting
Aly El Hakie*; Yiren Lu*; Yu Yin; Michael W. Jenkins; Yehe Liu. (* equal contribution)
We propose Noise Guided Splatting to address false transparency artifacts in 3D Gaussian Splatting by injecting opaque noise Gaussians in object volumes during training.

BARD-GS: Blur-Aware Reconstruction of Dynamic Scenes via Gaussian Splatting
Yiren Lu; Yunlai Zhou; Disheng Liu; Tuo Liang; Yu Yin.
CVPR 2025
We introduce BARD-GS, a robust dynamic scene reconstruction method that explicitly decomposes motion blur into camera and object components to handle blurry inputs and imprecise camera poses.
BARD-GS: Blur-Aware Reconstruction of Dynamic Scenes via Gaussian Splatting
Yiren Lu; Yunlai Zhou; Disheng Liu; Tuo Liang; Yu Yin.
We introduce BARD-GS, a robust dynamic scene reconstruction method that explicitly decomposes motion blur into camera and object components to handle blurry inputs and imprecise camera poses.
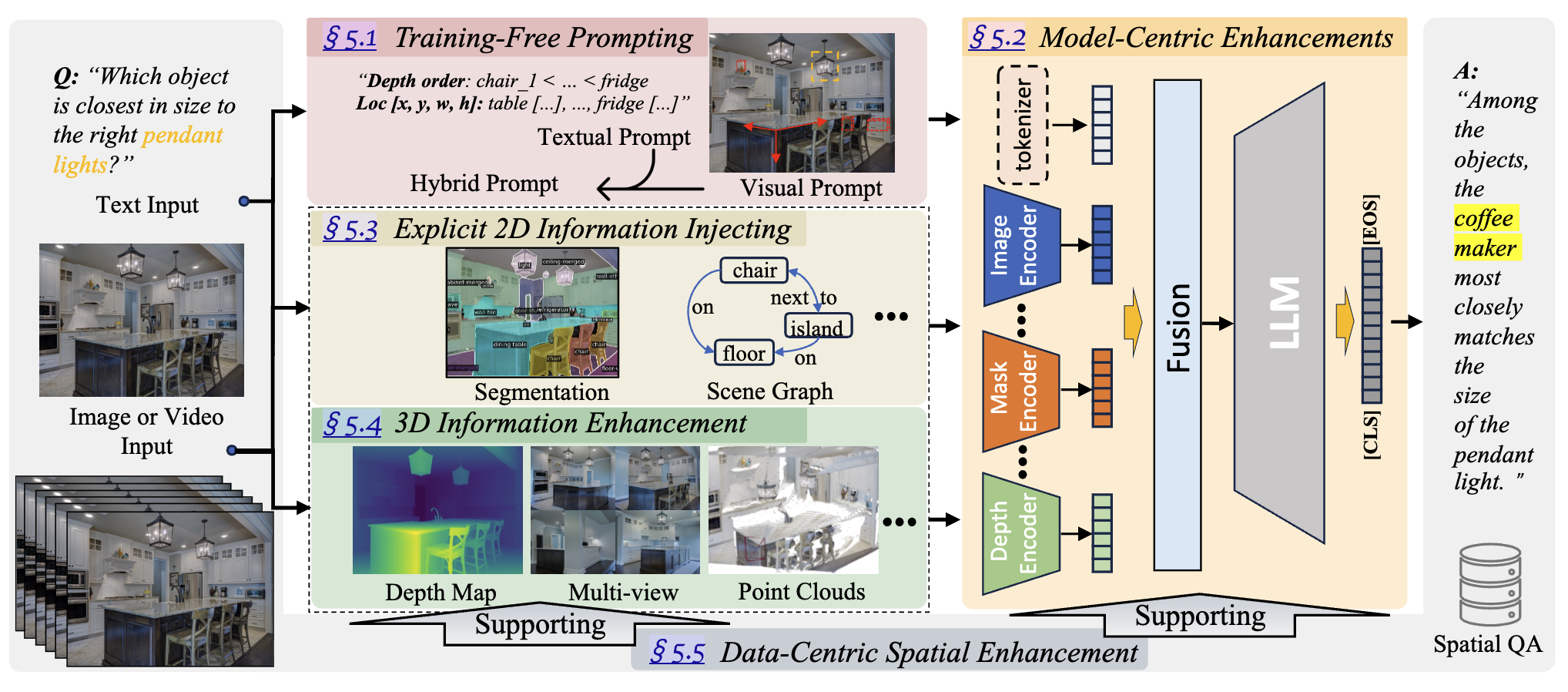

Counterfactual Visual Explanation via Causally-Guided Adversarial Steering
Yiran Qiao; Disheng Liu; Yiren Lu; Yu Yin; Mengnan Du; Jing Ma.
arXiv preprint 2025
We propose a causally-guided adversarial framework for counterfactual visual explanation that avoids spurious perturbations and improves explanation quality.
Counterfactual Visual Explanation via Causally-Guided Adversarial Steering
Yiran Qiao; Disheng Liu; Yiren Lu; Yu Yin; Mengnan Du; Jing Ma.
We propose a causally-guided adversarial framework for counterfactual visual explanation that avoids spurious perturbations and improves explanation quality.
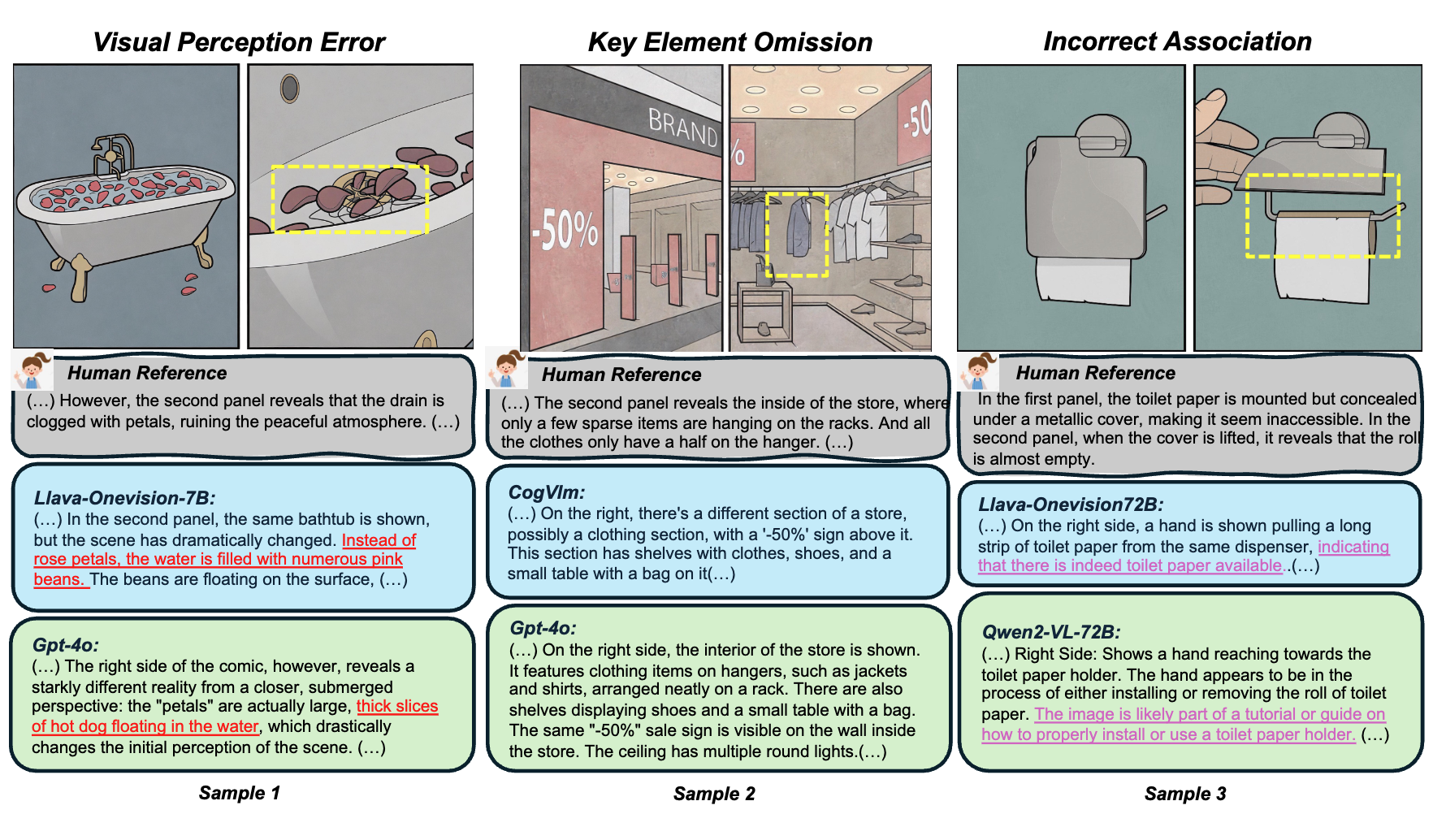
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Tuo Liang; Zhe Hu; Jing Li; Hao Zhang; Yiren Lu; Yunlai Zhou; Yiran Qiao; Disheng Liu; Jeirui Peng; Jing Ma; Yu Yin.
arXiv preprint 2025
Extension of Yes-But, Yes-But (V2).
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Tuo Liang; Zhe Hu; Jing Li; Hao Zhang; Yiren Lu; Yunlai Zhou; Yiran Qiao; Disheng Liu; Jeirui Peng; Jing Ma; Yu Yin.
Extension of Yes-But, Yes-But (V2).

CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data
Disheng Liu; Yiran Qiao; Wuche Liu; Yiren Lu; Yunlai Zhou; Tuo Liang; Yu Yin; Jing Ma.
arXiv 2025
We introduce Causal3D, a novel and comprehensive benchmark that integrates structured data (tables) with corresponding visual representations (images) to evaluate causal reasoning.
CAUSAL3D: A Comprehensive Benchmark for Causal Learning from Visual Data
Disheng Liu; Yiran Qiao; Wuche Liu; Yiren Lu; Yunlai Zhou; Tuo Liang; Yu Yin; Jing Ma.
We introduce Causal3D, a novel and comprehensive benchmark that integrates structured data (tables) with corresponding visual representations (images) to evaluate causal reasoning.
2024

View-consistent Object Removal in Radiance Fields
Yiren Lu; Jing Ma; Yu Yin.
ACM MM 2024
We introduce a novel radiance field editing pipeline that significantly enhances consistency by requiring inpainting of only a single reference image.
View-consistent Object Removal in Radiance Fields
Yiren Lu; Jing Ma; Yu Yin.
We introduce a novel radiance field editing pipeline that significantly enhances consistency by requiring inpainting of only a single reference image.
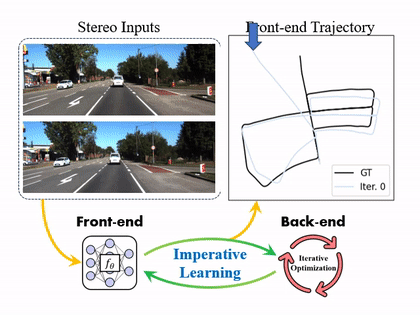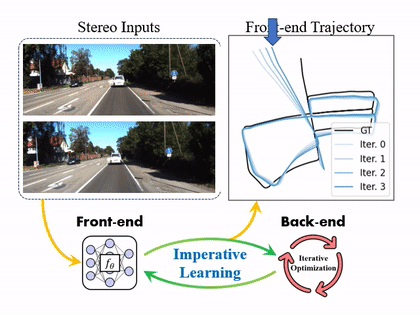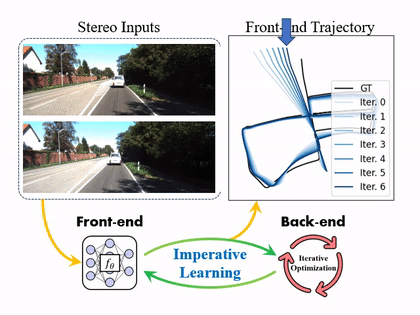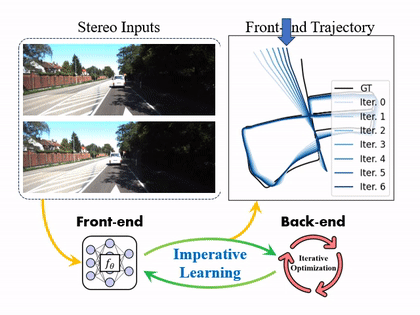
iSLAM: Imperative SLAM
Taimeng Fu; Shaoshu Su; Yiren Lu; Chen Wang.
Robotics and Automation Letters (RA-L) 2024
We proposed a novel self-supervised imperative learning framework, named imperative SLAM (iSLAM), which fosters reciprocal correction between the front-end and back-end and enhances performance without external supervision.
iSLAM: Imperative SLAM
Taimeng Fu; Shaoshu Su; Yiren Lu; Chen Wang.
We proposed a novel self-supervised imperative learning framework, named imperative SLAM (iSLAM), which fosters reciprocal correction between the front-end and back-end and enhances performance without external supervision.
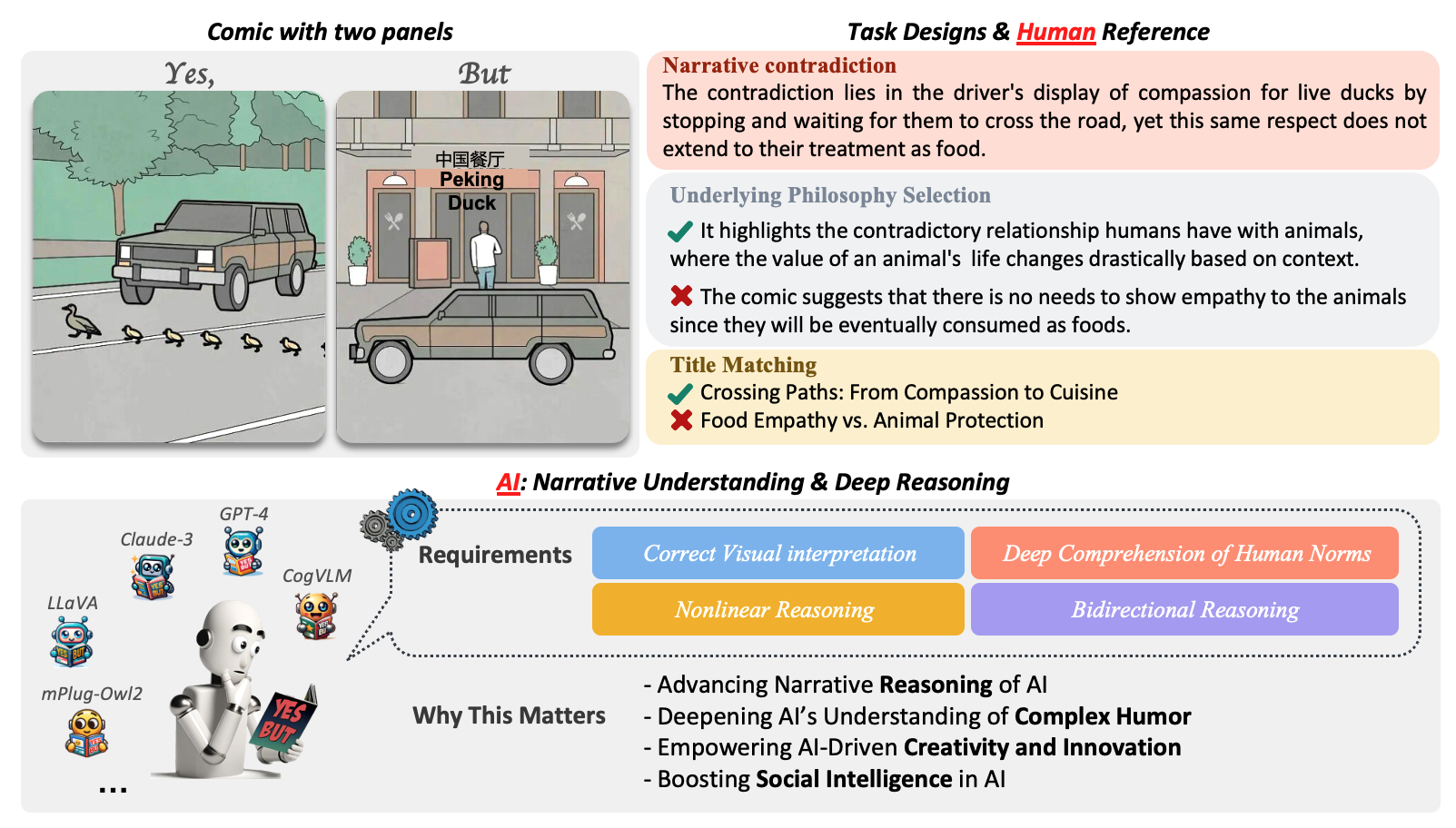
Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions
Zhe Hu; Tuo Liang; Jing Li; Yiren Lu; Yunlai Zhou; Yiran Qiao; Jing Ma; Yu Yin.
NeurIPS 2024
We introduce the YesBut benchmark, which comprises tasks aimed at assessing AI's capabilities in understanding comics with contradictory narratives.
Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions
Zhe Hu; Tuo Liang; Jing Li; Yiren Lu; Yunlai Zhou; Yiran Qiao; Jing Ma; Yu Yin.
We introduce the YesBut benchmark, which comprises tasks aimed at assessing AI's capabilities in understanding comics with contradictory narratives.
2023

PyPose v0.6: The Imperative Programming Interface for Robotics
Zitong Zhan; Xiangfu Li; Qihang Li; Haonan He; Abhinav Pandey; Haitao Xiao; Yangmengfei Xu; Xiangyu Chen; Kuan Xu; Kun Cao; Zhipeng Zhao; Zihan Wang; Huan Xu; Zihang Fang; Yutian Chen; Wentao Wang; Xu Fang; Yi Du; Tianhao Wu; Xiao Lin; Yuheng Qiu; Fan Yang; Jingnan Shi; Shaoshu Su; Yiren Lu; Taimeng Fu; Karthik Dantu; Jiajun Wu; Lihua Xie; Marco Hutter; Luca Carlone; Sebastian Scherer; Daning Huang; Yaoyu Hu; Junyi Geng; Chen Wang.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) Workshop 2023
PyPose v0.6: The Imperative Programming Interface for Robotics
Zitong Zhan; Xiangfu Li; Qihang Li; Haonan He; Abhinav Pandey; Haitao Xiao; Yangmengfei Xu; Xiangyu Chen; Kuan Xu; Kun Cao; Zhipeng Zhao; Zihan Wang; Huan Xu; Zihang Fang; Yutian Chen; Wentao Wang; Xu Fang; Yi Du; Tianhao Wu; Xiao Lin; Yuheng Qiu; Fan Yang; Jingnan Shi; Shaoshu Su; Yiren Lu; Taimeng Fu; Karthik Dantu; Jiajun Wu; Lihua Xie; Marco Hutter; Luca Carlone; Sebastian Scherer; Daning Huang; Yaoyu Hu; Junyi Geng; Chen Wang.
2022
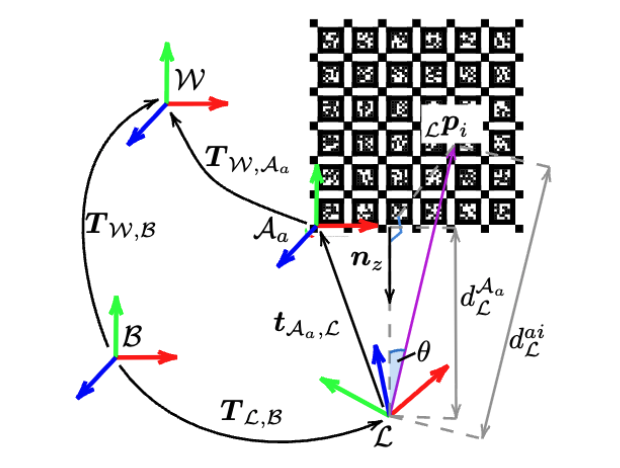
Multical: Spatiotemporal calibration for multiple IMUs, cameras and LiDARs
Xiangyang Zhi; Jiawei Hou; Yiren Lu; Laurent Kneip; Soren Schwertfeger.
IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) 2022
This paper presents a general sensor calibration method, named Multical, that makes use of multiple planar calibration targets whose poses will be estimated alongside spatiotemporal calibration.
Multical: Spatiotemporal calibration for multiple IMUs, cameras and LiDARs
Xiangyang Zhi; Jiawei Hou; Yiren Lu; Laurent Kneip; Soren Schwertfeger.
This paper presents a general sensor calibration method, named Multical, that makes use of multiple planar calibration targets whose poses will be estimated alongside spatiotemporal calibration.
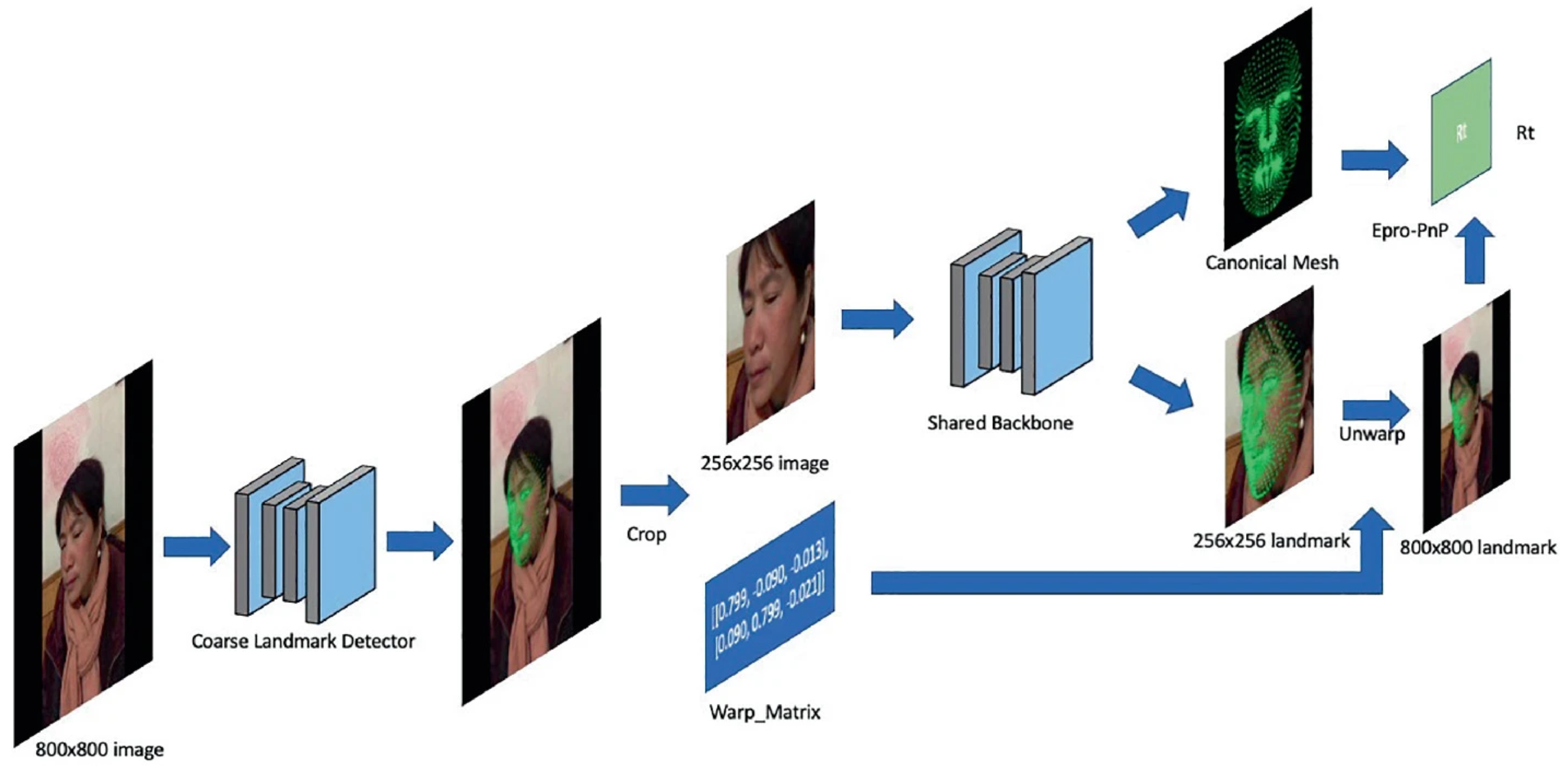
End to End Face Reconstruction via Differentiable PnP
Yiren Lu; Huawei Wei.
European Conference on Computer Vision 2022
2020

Improving CNN-based planar object detection with geometric prior knowledge
Jianxiong Cai; Jiawei Hou; Yiren Lu; Hongyu Chen; Laurent Kneip; Soren Schwertfeger.
IEEE International Symposium on Safety, Security, and Rescue Robotics 2020
Improving CNN-based planar object detection with geometric prior knowledge
Jianxiong Cai; Jiawei Hou; Yiren Lu; Hongyu Chen; Laurent Kneip; Soren Schwertfeger.